Part 1 · CogniVault Architecture: Why Standard RAG Isn't Enough (Hybrid Search)
All abbreviations are fully explained in the appendix at the bottom of the page.
Vector search is the process of finding the most similar items in a dataset based on their vector embeddings. This is how RAG systems usually work. But what happens when you need to find the most similar items in a dataset based not only on their semantic meaning but also on the exact wording of the query?
This becomes critical when the information you’re looking for isn’t just related but must match a specific string or keyword exactly.
Two ways of finding a book
Picture a good local bookshop. The owner has read everything, and she recommends by feel. Tell her you loved The Martian and she hands you Project Hail Mary — different title, different plot, but the same DNA: a lone scientist, an impossible survival problem, jokes under pressure. Ask for “something like Pride and Prejudice” and you’ll walk out with Emma. She isn’t matching words. She’s matching meaning.
Now ask her a different kind of question: “I need the book with ISBN 978-0-553-41802-6,” or “the manual that mentions error code 404B on the cover.” Her superpower is useless here. No amount of literary intuition finds an exact string. For that, you walk to the till and check the catalogue — a boring, literal index that knows exactly which shelf holds which identifier, and nothing about vibes.
A well-run bookshop needs both. So does a well-run RAG system:
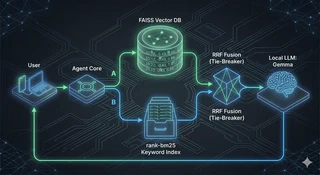
- FAISS — Facebook AI Similarity Search (the well-read owner): a vector index that finds chunks of text whose meaning is mathematically close to your prompt. Brilliant for “how is the practical exam structured?”, blind to “§3 Absatz 2”.
- BM25 — Best Match 25 (the catalogue): a classic keyword-scoring algorithm that rewards exact word matches, weighted by how rare and distinctive those words are. Brilliant for identifiers and quoted phrases, blind to paraphrase.
CogniVault runs both retrievers on every search — this is Hybrid Search — and then merges the two ranked lists with a formula called Reciprocal Rank Fusion (RRF). RRF scores each chunk purely by its position in each list: a chunk ranked highly by either retriever scores well, and a chunk both retrievers agree on rises to the top. Because only ranks are used, the two retrievers’ incompatible scoring scales never have to be reconciled.
The agent decides when to search
Here’s the part most diagrams get backwards (mine included, in an earlier draft): retrieval doesn’t happen before the model gets involved. It happens inside the model’s own loop.
CogniVault wraps Gemma in the Strands Agents SDK. The model receives your question along with a set of Tools (pre-written Python functions like search_knowledge_base, calculator, or compare_documents). It then reasons about the question and decides for itself whether — and which — tools to call. For most document questions it calls search_knowledge_base, reads the retrieved chunks, and only then writes its answer, grounded in what it found.
Here is the architectural blueprint of that loop:
One subtlety worth noting: the agent is Gemma. There is no separate “formatting model” at the end — the same model that decided to search also writes the final answer, now with the retrieved chunks in front of it.
What’s Next?
Building a toy RAG app is easy, but building one that actually retrieves the exact document you need requires hybrid engines and an agent that knows when to use them.
Want to see how this system safely ingests massive documents without losing work when something crashes? Read Part 2: Durable Ingestion with DBOS
Or, if you prefer to jump straight into the code, the hybrid search lives in backend/services/vector_db.py of the CogniVault repository on GitHub.
Appendix: Abbreviations in this post
| Abbreviation | Full form | Meaning |
|---|---|---|
| RAG | Retrieval-Augmented Generation | Retrieve relevant passages from your own documents first; let the model answer from them instead of from training memory |
| FAISS | Facebook AI Similarity Search | Meta’s library for storing vectors and finding the most similar ones fast |
| BM25 | Best Match 25 | A keyword-ranking formula — the 25th ranking function developed in the Okapi information-retrieval system |
| RRF | Reciprocal Rank Fusion | A formula that merges multiple ranked lists using only each item’s rank: score = Σ 1/(k + rank) |
| LLM | Large Language Model | A neural network trained on huge amounts of text that can read and generate language |
| SDK | Software Development Kit | A library of building blocks — here, Strands, which provides the agent loop |
| API | Application Programming Interface | The set of URLs the frontend calls to talk to the backend |
| ISBN | International Standard Book Number | The unique identifier printed on every published book — the catalogue’s best friend |

Related
- CogniVault Backend Explained, Part 1 · Meet the Backend: Three Processes, Four Layers
- CogniVault Backend Explained, Part 2 · From File to Searchable Knowledge
- Part 2 · CogniVault Architecture: Durable Ingestion with DBOS
- CogniVault Backend Explained, Part 3 · How a Question Becomes a Cited Answer
- Gemma CogniVault