Teil 3 · CogniVault Architektur: Warum wir Ollama nicht in Docker packen
Alle Abkürzungen werden im Anhang am Ende der Seite ausführlich erklärt.
Die goldene Regel für modernes Software-Deployment heißt Containerisierung. Pack alles in Docker, um die Abhängigkeiten zu isolieren, und es läuft auf jeder Maschine absolut identisch.
Als ich CogniVault anfangs entworfen habe, war der erste Impuls, den FastAPI-Server, die PostgreSQL-Datenbank und die Ollama LLM-Engine in ein einziges, sicheres Docker-Netzwerk zu stecken.
Aber das haben wir nicht getan. Wir haben Ollama nativ auf dem Host-System laufen lassen. Schauen wir uns mal an, warum.
Das GPU-Passthrough-Problem
Stell dir deine GPU wie die Küche in einem Restaurant vor. Die Köche (deine KI-Modelle) müssen in der Küche sein — am Herd stehen, die Hände an den Geräten. Stell dir nun vor, du sagst den Köchen, sie müssten aus einem verschlossenen Konferenzraum am Ende des Flurs kochen und Anweisungen durch eine Durchreiche rufen. Technisch gesehen kommt vielleicht immer noch Essen heraus. Aber es wird nicht schnell gehen.
Dieser verschlossene Raum ist ein Container. Large Language Models wie Gemma 4 brauchen direkten, ungehinderten Zugriff auf die GPU deiner Hardware (wie Apple Silicons Unified Memory oder eine dedizierte Nvidia-Karte), um Text schnell genug für ein Echtzeit-Chat-Interface zu generieren. Und die Situation ist je nach Plattform unterschiedlich:
- Auf macOS lässt Docker Container in einer ressourcenschonenden virtuellen Maschine laufen — und es gibt aktuell überhaupt kein GPU (Metal) Passthrough. Ein Ollama-Container auf einem Mac läuft also nur über die CPU. Für eine Chat-App ist das an sich schon ein K.o.-Kriterium.
- Unter Linux gibt es Nvidia GPU-Passthrough und es funktioniert auch, aber es erfordert zusätzliche Toolkit-Konfiguration, die die “es funktioniert einfach”-Philosophie der lokalen Entwicklung zunichte macht.
Wenn man Ollama nativ laufen lässt, umgeht man diese ganze Kategorie von Problemen.
Die Brückenlösung
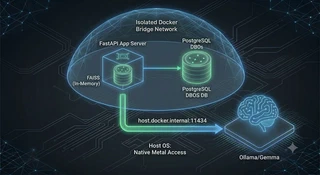
CogniVault verwendet ein geteiltes Deployment-Modell, das die Anwendungslogik von der rechenintensiven KI-Verarbeitung trennt.
- Die sicheren Räume (Docker): PostgreSQL — wo das DBOS-Workflow-Ledger aus Teil 2 liegt — befindet sich in einem Docker Bridge Network (einem privaten virtuellen Netzwerk). Isoliert, sauber, reproduzierbar.
- Das Hauptgebäude (Nativer Host): Ollama läuft direkt auf deinem Mac-, Windows- oder Linux-Betriebssystem und hat so direkten Zugriff auf deine GPU.
CogniVault wird tatsächlich mit zwei Ausführungsmodi ausgeliefert, und es lohnt sich, hier genau zu sein:
- Der Standardmodus (
scripts/start.sh): Nur PostgreSQL läuft in Docker. Das FastAPI-Backend läuft ebenfalls nativ (python -m backend.main), direkt neben Ollama. Das ist der einfachste Loop für die lokale Entwicklung. - Der vollcontainerisierte Modus (
docker-compose.yaml): Die FastAPI-App gesellt sich zu Postgres ins Compose-Netzwerk. In diesem Modus erreicht der App-Container die native Ollama-Engine über eine spezielle Docker-Routing-Adresse:host.docker.internal:11434.
So oder so bleibt die Regel die gleiche: Das Modell kommt niemals in die Box.
Was ist mit der Vektor-Datenbank?
Dir fällt vielleicht auf, dass FAISS hier kein Container ist. Im Gegensatz zu massiven SQL-Datenbanken ist FAISS extrem leichtgewichtig. In CogniVault läuft FAISS direkt im Speicher des FastAPI-Python-Prozesses und speichert seine Daten in einem lokalen Ordner. Es braucht keinen eigenen Container.
Indem wir die schwere LLM-Arbeit direkt auf der Hardware (Bare-Metal) erledigen und die Buchhaltung in Containern belassen, erreichen wir genau die Balance, an der die lokale KI-Entwicklung so oft scheitert: null Abhängigkeitskonflikte kombiniert mit maximaler KI-Performance.
Erlebe es in Aktion
Das schließt unsere CogniVault-Architekturserie ab! Wenn du diesen zu 100% lokalen, datenschutzfreundlichen Lernbegleiter auf deiner eigenen Hardware ausführen möchtest:
- Hol dir den Code: CogniVault auf GitHub
- Schau dir das Walkthrough an: Vollständige Demo auf YouTube
Anhang: Abkürzungen in diesem Beitrag
| Abbreviation | Full form | Meaning |
|---|---|---|
| GPU | Graphics Processing Unit | Die Hardware, die lokale Modell-Inferenz schnell macht; Container haben Probleme, darauf zuzugreifen |
| LLM | Large Language Model | Ein auf riesigen Textmengen trainiertes neuronales Netzwerk, das Sprache lesen und erzeugen kann |
| AI | Artificial Intelligence | Software, die Aufgaben ausführt, für die normalerweise menschliche Intelligenz erforderlich ist |
| API | Application Programming Interface | Die URLs, die das Frontend aufruft, um mit dem Backend zu kommunizieren |
| HTTP | HyperText Transfer Protocol | Das Protokoll, mit dem Browser und APIs Anfragen und Antworten austauschen |
| OS | Operating System | macOS, Windows oder Linux — wo Ollama nativ läuft |
| DBOS | Database-Oriented Operating System | Die Durable-Workflow-Bibliothek, deren Ledger im Postgres-Container liegt (siehe Teil 2) |
| SQL | Structured Query Language | Die Sprache relationaler Datenbanken wie PostgreSQL |
| FAISS | Facebook AI Similarity Search | Der In-Process-Vektorindex — absichtlich kein separater Container |
| VM | Virtual Machine | Die versteckte Schicht, die Docker auf macOS nutzt — und der Grund, warum Mac-Container die GPU nicht erreichen können |
