Teil 1 · CogniVault Architektur: Warum Standard-RAG nicht reicht (Hybride Suche)
Alle Abkürzungen werden im Anhang am Ende der Seite ausführlich erklärt.
Vektorsuche ist der Prozess, bei dem die ähnlichsten Elemente in einem Datensatz basierend auf ihren Vektor-Embeddings gefunden werden. So funktionieren RAG-Systeme normalerweise. Aber was passiert, wenn du die ähnlichsten Elemente in einem Datensatz nicht nur aufgrund ihrer semantischen Bedeutung, sondern auch anhand des exakten Wortlauts der Suchanfrage finden musst?
Das wird kritisch, wenn die Information, die du suchst, nicht nur inhaltlich verwandt sein soll, sondern genau mit einer bestimmten Zeichenkette oder einem bestimmten Schlüsselwort übereinstimmen muss.
Zwei Wege, ein Buch zu finden
Stell dir eine gute lokale Buchhandlung vor. Die Besitzerin hat alles gelesen und empfiehlt nach Gefühl. Sag ihr, dass du Der Marsianer geliebt hast, und sie gibt dir Project Hail Mary — anderer Titel, andere Handlung, aber dieselbe DNA: ein einsamer Wissenschaftler, ein unmögliches Überlebensproblem, Witze unter Druck. Frag nach “sowas wie Stolz und Vorurteil” und du gehst mit Emma raus. Sie gleicht keine Wörter ab. Sie gleicht Bedeutung ab.
Nun stell ihr eine andere Art von Frage: “Ich brauche das Buch mit der ISBN 978-0-553-41802-6” oder “das Handbuch, auf dessen Cover der Fehlercode 404B erwähnt wird.” Ihre Superkraft ist hier nutzlos. Keine noch so große literarische Intuition findet einen exakten String. Dafür gehst du zur Kasse und schaust in den Katalog — einen langweiligen, wörtlichen Index, der genau weiß, welches Regal welche Kennung enthält, und dem “Vibes” völlig egal sind.
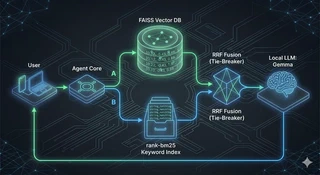
Eine gut geführte Buchhandlung braucht beides. Genauso wie ein gut geführtes RAG-System:
- FAISS — Facebook AI Similarity Search (die belesene Besitzerin): ein Vektorindex, der Textabschnitte findet, deren Bedeutung mathematisch nah an deinem Prompt liegt. Genial für “Wie ist die praktische Prüfung aufgebaut?”, aber blind für “§3 Absatz 2”.
- BM25 — Best Match 25 (der Katalog): ein klassischer Keyword-Scoring-Algorithmus, der exakte Worttreffer belohnt, gewichtet danach, wie selten und markant diese Wörter sind. Genial für Identifikatoren und zitierte Phrasen, aber blind für Umschreibungen (Paraphrasen).
CogniVault führt bei jeder Suche beide Retriever aus — das nennt man Hybride Suche (Hybrid Search) — und führt dann die beiden Ranglisten mit einer Formel namens Reciprocal Rank Fusion (RRF) zusammen. RRF bewertet jeden Chunk rein nach seiner Position in jeder Liste: Ein Chunk, der von einem der beiden Retriever hoch eingestuft wird, schneidet gut ab, und ein Chunk, bei dem sich beide Retriever einig sind, steigt nach ganz oben. Da nur Ränge verwendet werden, müssen die inkompatiblen Bewertungsskalen der beiden Retriever niemals in Einklang gebracht werden.
Der Agent entscheidet, wann gesucht wird
Hier ist der Teil, den die meisten Diagramme verdrehen (meins in einem früheren Entwurf eingeschlossen): Das Retrieval (die Abfrage) passiert nicht, bevor das Modell ins Spiel kommt. Es passiert innerhalb des eigenen Loops des Modells.
CogniVault verpackt Gemma im Strands Agents SDK. Das Modell erhält deine Frage zusammen mit einer Reihe von Tools (vorgeschriebene Python-Funktionen wie search_knowledge_base, calculator oder compare_documents). Es denkt dann über die Frage nach und entscheidet selbst, ob — und welche — Tools es aufruft. Bei den meisten Fragen zu Dokumenten ruft es search_knowledge_base auf, liest die abgerufenen Chunks und schreibt erst dann seine Antwort, basierend auf dem, was es gefunden hat.
Hier ist die Blaupause der Architektur dieses Loops:
Eine Feinheit, die erwähnenswert ist: Der Agent ist Gemma. Es gibt am Ende kein separates “Formatierungsmodell” — dasselbe Modell, das sich für die Suche entschieden hat, schreibt auch die endgültige Antwort, nun mit den abgerufenen Chunks vor Augen.
Was kommt als Nächstes?
Eine Spielzeug-RAG-App zu bauen ist einfach, aber eine zu bauen, die tatsächlich genau das Dokument abruft, das du brauchst, erfordert hybride Engines und einen Agenten, der weiß, wann er sie einsetzen muss.
Willst du sehen, wie dieses System riesige Dokumente sicher einliest, ohne Arbeit zu verlieren, wenn mal etwas abstürzt? Lies Teil 2: Dauerhafte Ingestion mit DBOS
Oder, wenn du lieber direkt in den Code springen willst: Die hybride Suche befindet sich in backend/services/vector_db.py des CogniVault-Repositories auf GitHub.
Anhang: Abkürzungen in diesem Beitrag
| Abbreviation | Full form | Meaning |
|---|---|---|
| RAG | Retrieval-Augmented Generation | Rufe zuerst relevante Passagen aus deinen eigenen Dokumenten ab; lass das Modell daraus antworten anstatt aus dem Trainingsgedächtnis |
| FAISS | Facebook AI Similarity Search | Metas Bibliothek zum Speichern von Vektoren und zum schnellen Finden der ähnlichsten |
| BM25 | Best Match 25 | Eine Keyword-Ranking-Formel — die 25. Ranking-Funktion, die im Okapi-Information-Retrieval-System entwickelt wurde |
| RRF | Reciprocal Rank Fusion | Eine Formel, die mehrere Ranglisten nur anhand des Rangs jedes Elements zusammenführt: score = Σ 1/(k + rank) |
| LLM | Large Language Model | Ein auf riesigen Textmengen trainiertes neuronales Netzwerk, das Sprache lesen und erzeugen kann |
| SDK | Software Development Kit | Eine Bibliothek mit Bausteinen — hier Strands, was den Agent-Loop bereitstellt |
| API | Application Programming Interface | Die URLs, die das Frontend aufruft, um mit dem Backend zu kommunizieren |
| ISBN | International Standard Book Number | Die eindeutige Kennung, die auf jedem veröffentlichten Buch gedruckt ist — der beste Freund des Katalogs |

Ähnliches
- CogniVault Backend erklärt, Teil 1 · Das Backend kennenlernen: Drei Prozesse, vier Schichten
- CogniVault Backend erklärt, Teil 2 · Von der Datei zum durchsuchbaren Wissen
- Teil 2 · CogniVault Architektur: Dauerhafte Ingestion mit DBOS
- CogniVault Backend erklärt, Teil 3 · Wie aus einer Frage eine belegte Antwort wird
- Gemma CogniVault