Part 2 · CogniVault Architecture: Durable Ingestion with DBOS
All abbreviations are fully explained in the appendix at the bottom of the page.
In a basic local AI setup, adding documents to your database is usually just a simple Python script. You open a PDF, chop the text into chunks, turn those chunks into math (embeddings), and save them.
This works great for a five-page essay. But what happens when you are ingesting a 1,000-page technical manual and your laptop goes to sleep at page 800?
The script dies. When you wake your laptop up, you have to start all over from page 1, wasting time and compute power. A simple script wasn’t going to cut it for CogniVault. We needed a Durable Workflow.
The Factory Ledger (DBOS)
Think of data ingestion like a factory assembly line. If the power goes out, the workers shouldn’t have to rebuild every product from scratch. They should just look at a permanent ledger, see exactly which box they were packing when the lights went out, and resume from there.
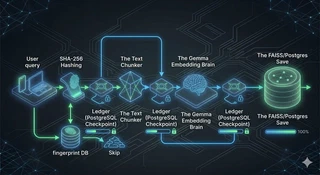
CogniVault uses a framework called DBOS (Database-Oriented Operating System) backed by a PostgreSQL database to act as this ledger.
Every step of the ingestion process records its completion in Postgres. If the server crashes mid-way, nothing dramatic happens in the moment — the magic is on restart: DBOS reads the ledger, sees which steps already finished, replays their recorded results instantly, and resumes from the first unfinished step.
One important boundary: Postgres holds only the ledger — which steps ran and what they returned. Your documents, chunks, and vectors never live there. They go to a FAISS index plus a JSON metadata file on disk.
SHA-256 Hashing: The Idempotency Trick
The system also needs to be smart about re-uploads. If you fix a typo in a massive document and upload it again, you don’t want the system to waste 10 minutes re-embedding the whole thing.
CogniVault achieves Idempotency (the ability to run the same operation multiple times without changing the result beyond the initial application) with the workflow’s very first step: it scans the docs/ folder and generates a SHA-256 hash (a unique digital fingerprint) for every file.
- If the hash is new, it processes the file.
- If the hash has changed (because you edited the file), it soft-deletes the old text chunks and only re-embeds the new version.
- If the hash is identical, it skips the file entirely.
We can see here how this flows logically:
(A detail for the curious: the checkpointed steps are the scan, the per-document extraction, each embedding batch, and the save. The chunking in between is fast pure-Python work, so it simply re-runs as part of the workflow body — checkpointing it would cost more than redoing it.)
What’s Next?
By wrapping the ingestion pipeline in DBOS, the system transforms from a fragile script into a resilient, production-grade state machine.
Now that our data is safely ingested, how do we deploy this entire pipeline without melting our laptop’s GPU? Read Part 3: Why We Keep Ollama Out of Docker
You can also explore the DBOS implementation directly in the backend/services/ingest.py file of the CogniVault repository.
Appendix: Abbreviations in this post
| Abbreviation | Full form | Meaning |
|---|---|---|
| DBOS | Database-Oriented Operating System | A library that checkpoints workflow steps in a database so crashed jobs resume instead of restarting |
| SHA-256 | Secure Hash Algorithm, 256-bit | A fingerprint function: any file maps to a unique 64-character hash; change one byte and the hash changes completely |
| Portable Document Format | The document format whose text (and scans) the pipeline extracts | |
| FAISS | Facebook AI Similarity Search | Meta’s vector-search library — where the embeddings actually live |
| JSON | JavaScript Object Notation | The text format used for the chunk-metadata file stored next to the FAISS index |
| AI | Artificial Intelligence | Software performing tasks that normally need human intelligence |
| GPU | Graphics Processing Unit | The hardware that makes local model inference fast — the subject of Part 3 |

Related
- Part 1 · CogniVault Architecture: Why Standard RAG Isn't Enough (Hybrid Search)
- CogniVault Backend Explained, Part 2 · From File to Searchable Knowledge
- Part 4 · Crash-Resumable Ingestion: DBOS, SHA-256, and Surviving a kill -9
- Part 3 · CogniVault Architecture: Why We Keep Ollama Out of Docker
- CogniVault Backend Explained, Part 1 · Meet the Backend: Three Processes, Four Layers