Teil 2 · CogniVault Architektur: Dauerhafte Ingestion mit DBOS
Alle Abkürzungen werden im Anhang am Ende der Seite ausführlich erklärt.
In einem einfachen lokalen KI-Setup ist das Hinzufügen von Dokumenten zu deiner Datenbank normalerweise nur ein simples Python-Skript. Du öffnest ein PDF, zerhackst den Text in Chunks, verwandelst diese Chunks in Mathe (Embeddings) und speicherst sie.
Das funktioniert super für ein fünfseitiges Essay. Aber was passiert, wenn du ein 1.000-seitiges technisches Handbuch einliest (Ingestion) und dein Laptop bei Seite 800 in den Ruhemodus geht?
Das Skript stirbt. Wenn du deinen Laptop aufweckst, musst du wieder bei Seite 1 anfangen und verschwendest so Zeit und Rechenleistung. Ein einfaches Skript reichte für CogniVault nicht aus. Wir brauchten einen Durable Workflow (dauerhaften Workflow).
Das Fabrikbuch (DBOS)
Stell dir die Daten-Ingestion wie ein Fließband in einer Fabrik vor. Wenn der Strom ausfällt, sollten die Arbeiter nicht jedes Produkt von Grund auf neu bauen müssen. Sie sollten einfach in ein permanentes Kassenbuch (Ledger) schauen, genau sehen, welche Kiste sie gerade gepackt haben, als das Licht ausging, und dort weitermachen.
CogniVault verwendet ein Framework namens DBOS (Database-Oriented Operating System), das von einer PostgreSQL-Datenbank gestützt wird, um als dieses Buch zu fungieren.
Jeder Schritt des Ingestion-Prozesses protokolliert seinen Abschluss in Postgres. Wenn der Server mittendrin abstürzt, passiert im Moment nichts Dramatisches — die Magie entfaltet sich beim Neustart: DBOS liest das Buch, sieht, welche Schritte bereits abgeschlossen sind, spielt die aufgezeichneten Ergebnisse sofort ab und macht beim ersten unvollendeten Schritt weiter.
Eine wichtige Grenze: Postgres enthält nur das Buch — welche Schritte gelaufen sind und was sie zurückgegeben haben. Deine Dokumente, Chunks und Vektoren leben dort nie. Sie wandern in einen FAISS-Index plus eine JSON-Metadaten-Datei auf der Festplatte.
SHA-256 Hashing: Der Idempotenz-Trick
Das System muss auch bei erneuten Uploads clever sein. Wenn du einen Tippfehler in einem riesigen Dokument behebst und es noch einmal hochlädst, willst du nicht, dass das System 10 Minuten verschwendet, um das Ganze neu einzubetten (re-embedding).
CogniVault erreicht Idempotenz (die Fähigkeit, dieselbe Operation mehrmals auszuführen, ohne das Ergebnis nach der ersten Anwendung zu verändern) mit dem allerersten Schritt des Workflows: Es scannt den docs/-Ordner und generiert einen SHA-256-Hash (einen einzigartigen digitalen Fingerabdruck) für jede Datei.
- Wenn der Hash neu ist, wird die Datei verarbeitet.
- Wenn sich der Hash geändert hat (weil du die Datei bearbeitet hast), löscht es die alten Text-Chunks per “Soft-Delete” und bettet nur die neue Version neu ein.
- Wenn der Hash identisch ist, überspringt es die Datei komplett.
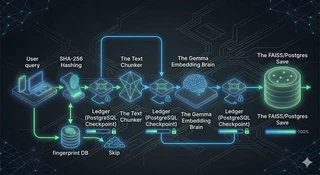
Hier können wir sehen, wie das logisch abläuft:
(Ein Detail für die Neugierigen: Die per Checkpoint gesicherten Schritte sind der Scan, die Extraktion pro Dokument, jeder Embedding-Batch und das Speichern. Das Chunking dazwischen ist schnelle, reine Python-Arbeit, also läuft es einfach als Teil des Workflow-Körpers erneut — es mit einem Checkpoint zu versehen, würde mehr kosten, als es neu zu machen.)
Was kommt als Nächstes?
Indem wir die Ingestion-Pipeline in DBOS verpacken, verwandelt sich das System von einem anfälligen Skript in eine robuste Zustandsmaschine (State Machine) auf Produktionsniveau.
Jetzt, da unsere Daten sicher eingelesen sind, wie deployen wir diese gesamte Pipeline, ohne die GPU unseres Laptops zum Schmelzen zu bringen? Lies Teil 3: Warum wir Ollama nicht in Docker packen
Du kannst die DBOS-Implementierung auch direkt in der Datei backend/services/ingest.py im CogniVault-Repository erkunden.
Anhang: Abkürzungen in diesem Beitrag
| Abbreviation | Full form | Meaning |
|---|---|---|
| DBOS | Database-Oriented Operating System | Eine Bibliothek, die Workflow-Schritte in einer Datenbank sichert, sodass abgestürzte Jobs fortgesetzt statt neu gestartet werden |
| SHA-256 | Secure Hash Algorithm, 256-bit | Eine Fingerabdruck-Funktion: Jede Datei wird auf einen einzigartigen 64-Zeichen-Hash abgebildet; änderst du ein Byte, ändert sich der Hash komplett |
| Portable Document Format | Das Dokumentenformat, dessen Text (und Scans) die Pipeline extrahiert | |
| FAISS | Facebook AI Similarity Search | Metas Vektorsuch-Bibliothek — wo die Embeddings tatsächlich leben |
| JSON | JavaScript Object Notation | Das Textformat, das für die Chunk-Metadaten-Datei neben dem FAISS-Index verwendet wird |
| AI | Artificial Intelligence | Software, die Aufgaben ausführt, für die normalerweise menschliche Intelligenz erforderlich ist |
| GPU | Graphics Processing Unit | Die Hardware, die lokale Modell-Inferenz schnell macht — das Thema von Teil 3 |

Ähnliches
- Teil 1 · CogniVault Architektur: Warum Standard-RAG nicht reicht (Hybride Suche)
- CogniVault Backend erklärt, Teil 2 · Von der Datei zum durchsuchbaren Wissen
- Teil 4 · Crash-Resumable Ingestion: DBOS, SHA-256 und wie man ein kill -9 überlebt
- Teil 3 · CogniVault Architektur: Warum wir Ollama nicht in Docker packen
- CogniVault Backend erklärt, Teil 1 · Das Backend kennenlernen: Drei Prozesse, vier Schichten